

DATA ON-AIR에서 25번 그룹 함수와 26번 윈도우 함수를 요약 정리한 내용이다.
데이터 분석 개요
ANSI/ISO SQL 표준은 데이터 분석을 위해서 다음 세 가지 함수를 정의하고 있다.
- 집계 함수(AGGREGATE FUNCTION)
- GROUP AGGREGATE FUNCTION이라고도 부르며, GROUP FUNCTION의 한 부분으로 분류
- COUNT, SUM, AVG, MAX, MIN 외 각종 집계 함수들
- 그룹 함수(GROUP FUNCTION)
- 하나의 SQL로 테이블을 한 번만 읽어서 빠르게 원하는 리포트를 작성할 수 있는 함수
- ROLLUP 함수, CUBE 함수, GROUPING SETS 함수가 있다.
- 윈도우 함수(WINDOW FUNCTION)
- 데이터웨어하우스에서 발전한 기능
- 분석 함수(ANALYTIC FUNCTION)나 순위 함수(RANK FUNCTION)로도 불린다.
그룹 함수
ROLLUP
ROLLUP 함수는 소그룹 간의 소계를 계산하는 함수이다.
- ROLLUP을 사용하면 GROUP BY로 묶은 각각의 소그룹 합계와 전체 합계를 모두 구할 수 있다.
- ROLLUP의 인수는 계층 구조이므로 인수의 순서가 중요하다.
- Grouping Columns의 수를 N이라 했을 때, N+1 LEVEL의 Subtotal이 생성된다.
- 그룹 함수를 지원하기 위해 GROUPING 함수가 추가되었다.
- ROLLUP이나 CUBE에 의한 소계가 계산된 결과에는 GROUPING(EXPR) = 1
- 그 외의 결과에는 GROUPING(EXPR) = 0
+ ROLLUP 함수 예제
SELECT DNAME, JOB, COUNT(*) 직원수, SUM(SAL) AS 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB) -- DNAME을 기준으로 소그룹 집계
ORDER BY DNAME, JOB;

+ ROLLUP에서 GROUPING 함수의 사용
GROUPING 함수는 SELECT문에 사용되어 고급 집계 함수를 보조하는 역할을 한다.
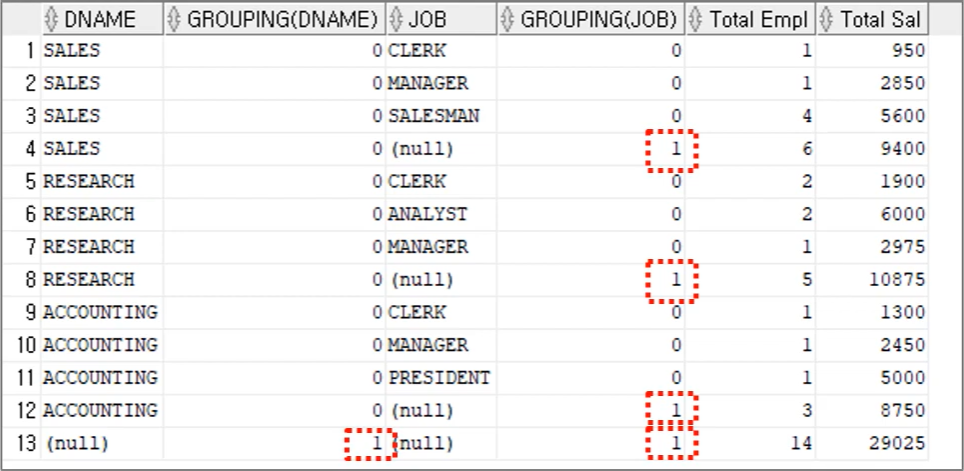
SELECT DNAME GROUPING(DNAME), JOB, GROUPING(JOB), COUNT(*) "Total Empl", SUM(SAL) "Total Sal"
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB);- GROUPING(DNAME), GROUPING(JOB) : DNAME과 JOB의 소계가 계산된 결과는 1, 그렇지 않은 결과는 0
- 그래서 JOB에 대한 GROUPING 결과는 총 3개, DNAME에 대한 GROUPING 결과는 총 1개이다.
+ GROUPING × CASE의 사용
심화 학습 내용
소계 결과명이 NULL로 표시되는 것에 이름을 붙이는 방법이라고 보면 된다.
SELECT
CASE GROUPING(DNAME)
WHEN 1 THEN 'All Departments' -- GROUPING의 결과가 1이라면 'All Departments'로 명명
ELSE DNAME
END AS DNAME,
CASE GROUPING(JOB)
WHEN 1 THEN 'All Jobs' -- GROUPING의 결과가 1이라면 'All Jobs'로 명명
ELSE JOB
END AS JOB,
COUNT(*) "Total Emp", SUM(SAL) "Total Sal"
FROM EMP, EDPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB);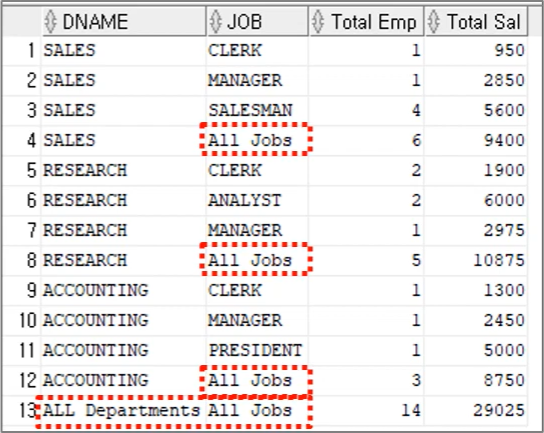
CUBE
ROLLUP에서는 단지 가능한 Subtotal만을 생성하였지만, CUBE는 결합 가능한 모든 값에 대하여 다차원 집계를 생성한다.
- 제시한 칼럼에 대해 결합 가능한 모든 집계(합의 경우의 수)를 계산한다.
- 내부적으로는 Grouping Columns의 순서를 바꾸어서 Query를 추가 수행하므로 인수의 순서는 무관하다.
- ROLLUP에 비해 시스템에 많은 부담을 주므로 사용에 주의해야 한다.
- Grouping Columns의 수를 N이라 했을 때, 2의 N승 LEVEL의 Subtotal이 생성된다.
+ CUBE 함수 예제
SELECT DNAME, JOB, COUNT(*) 직원수, SUM(SAL) 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY CUBE(DNAME, JOB) -- ( = GROUP BY CUBE(JOB, DNAME) / 순서 무관)
ORDER BY DNAME, JOB;
+ ROLLUP을 사용한 CUBE의 구현
위에서 제시한 CUBE 함수의 예제를 ROLLUP 함수를 사용해 구현하면 아래와 같다.
SELECT DNAME, JOB, COUNT(*) 직원수, SUM(SAL) AS 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(DNAME, JOB)
UNION
SELECT DNAME, JOB, COUNT(*) 직원수, SUM(SAL) AS 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY ROLLUP(JOB, DNAME)
ORDER BY DNAME, JOB;
GROUPING SETS
GROUPING SETS 함수는 GROUP BY에 나오는 칼럼의 순서와 관계없이 개별적으로 처리하여, 다양한 소계를 만들 수 있다. 쉽게 말하자면, 여러 칼럼 각각에 대해 반복적으로 그룹화를 하는 함수이다.
- GROUPING SETS에 표시된 인수들에 대한 개별 집계를 구할 수 있다.
- ROLLUP과는 달리 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같다. (CUBE와 동일)
- 결과에 대한 정렬이 필요한 경우는 ORDER BY 절에 명시적으로 정렬 칼럼이 표시가 되어야 한다.
- Grouping Columns의 수를 N이라 했을 때, 2의 N승 LEVEL의 Subtotal이 생성된다.
+ GROUPING SETS 함수 예제
SELECT DNAME, JOB, COUNT(*) 직원수, SUM(SAL) 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS(DNAME, JOB);
+ GROUPING × DECODE의 사용
CASE와 동일
SELECT
-- GROUPING의 결과가 1이라면 'All Departments'로 명명하고, 아니라면 DNAME으로 명명
DECODE(GROUPING(DNAME), 1, 'All Departments', DNAME) AS DNAME,
DECODE(GROUPING(JOB), 1, 'All Jobs', JOB) AS JOB,
COUNT(*) 직원수, SUM(SAL) 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
GROUP BY GROUPING SETS(DNAME, JOB);
+ GROUP BY와 UNION ALL을 사용한 GROUPING SETS의 구현
심화 학습 내용
SELECT 'All Departments' AS DNAME, JOB, COUNT(*) 직원수, SUM(SAL) 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPT.NO
GROUP BY JOB
UNION ALL -- 서로 겹칠 일이 없다는 것을 안다면, UNION ALL을 권장 (속도가 더 빠름)
SELECT DNAME, 'All Jobs' AS JOB, COUNT(*) 직원수, SUM(SAL) 급여합
FROM EMP, DEPT
WHERE DEPT.DEPTNO = EMP.DEPT.NO
GROUP BY DNAME;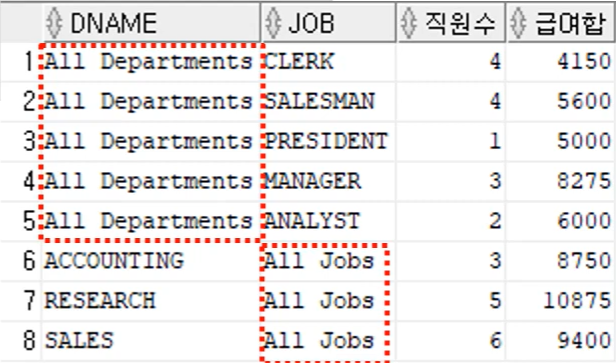
윈도우 함수
기존 관계형 DB는 칼럼 간 연산은 쉽지만 행간의 연산을 하나의 SQL 문으로 처리하는 것은 매우 어려운 문제였다. 그래서 행과 행간의 관계를 쉽게 정의하기 위해 만든 함수가 바로 WINDOW FUNCTION이다.
- 다른 함수와는 달리 중첩(Nested)해서 사용할 수 없다
- 서브쿼리에서 사용 가능하다.
SELECT WINDOW_FUNCTION(ARGUMENTS) OVER
([PARTITION BY 칼럼][ORDER BY 절][WINDOWING 절])
FROM 테이블명;- WINDOW_FUNCTION : 기존 함수 or WINDOW 함수로 추가된 함수
- ARGUMENTS(인수) : 함수에 따라 0 ~ N개의 인수 지정
- PARTITION BY 절 : 전제 집합을 기준에 의해 소그룹으로 나눌 수 있음
- ORDER BY 절 : 순서를 지정할 기준 항목
- WINDOWING 절 : 함수의 대상이 되는 행 기준의 범위를 지정 (ROWS / RANGE 중 하나를 선택해서 사용)
- ROWS : 행의 수를 기준으로 한 범위
- RANGE : 값을 기준으로 한 범위
| 표현식 | 해석 |
| ROWS BETWEEN 1 PRECEDING AND 1 FOLOWING | 해당 파티션 내에서 앞의 한 행, 현재 행, 뒤의 한 행을 범위로 지정 |
| RANGE BETWEEN 50 PRECEDING AND 150 FOLLOWING | 해당 파티션 내에서 (현재 행의 값 - 50) ~ (현재 행의 값 + 150)을 범위로 지정 |
| RANGE UNBOUNDED PRECEDING | 현재 파티션의 첫 행부터 현재 행까지 지정 |
+ 윈도우 함수의 종류
| 함수의 종류 | 설명 |
| 순위 | RANK, DENSE_RANK, ROW_NUMBER |
| 집계 | SUM, MAX, MIN, AVG, COUNT |
| 행 순서 | FIRST_VALUE, LAST_VALUE, LAG, LEAD |
| 비율 | RATIO_TO_REPORT, PERCENT_RANK, NTILE |
| 통계 분석 | CORR, STDDEV, VARIANCE |
순위 관련 함수
ORDER BY를 포함한 QUERY 문에서 특정 항목(칼럼)에 대한 순위를 구하는 함수이다.
| 함수 | 함수 설명 |
| RANK | - 동일한 값에는 동일한 순위를 부여 - 동일한 순위를 여러 건으로 취급 (1, 2, 2, 4) |
| DENSE_RANK | - 동일한 값에는 동일한 순위를 부여 - 동일한 순위를 한 건으로 취급 (1, 2, 2, 3) |
| ROW_NUMBER | - 동일한 값이라도 고유한 순위를 부여 (1, 2, 3, 4) |
+ RANK 함수를 사용한 전체 급여 순위, JOB 내에서 급여 순위 출력 예시
SELECT JOB, ENAME, SAL,
RANK() OVER (ORDER BY SAL DESC) AS ALL_RANK,
RANK() OVER (PARTITION BY JOB ORDER BY SAL DESC) AS JOB_RANK
FROM EMP;
+ RANK, DENSE_RANK, ROW_NUMBER 비교
SELECT JOB, ENAME, SAL,
RANK() OVER (ORDER BY SAL DESC) AS RANK,
DENSE_RANK() OVER (ORDER BY SAL DESC) AS DENSE_RANK,
ROW_NUMBER() OVER (ORDER BY SAL DESC) AS ROW_NUMBER,
FROM EMP;
집계 관련 함수
+ SUM
파티션 별 윈도우의 합을 구하는 함수
- 각 직업 내에서 본인보다 높은 급여를 받는 직원의 급여 총합(본인 포함)
SELECT JOB, ENAME, SAL,
SUM(SAL) OVER (PARTITION BY JOB ORDER BY SAL DESC RANGE UNBOUNDED PRECEDING)
-- RANGE UNBOUNDED PRECEDING : 첫 행부터 현재 행까지
AS JOB_SUM
FROM EMP;
- 각 직업 내에서 본인 바로 위, 본인, 본인 바로 아래의 급여 합 출력 예시
SELECT JOB, ENAME, SAL,
SUM(SAL) OVER (PARTITION BY JOB ORDER BY SAL ASC ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
AS JOB_SUM
FROM EMP;
+ MAX / MIN
파티션 별 윈도우의 최대 / 최소값을 구하는 함수
- 각 직원이 속한 직업 내에서 급여의 최대값을 함께 출력하기 위한 예시
SELECT JOB, ENAME, SAL,
MAX(SAL) OVER (PARTITION BY JOB) JOB_MAX
MAX(SAL) OVER () JOB_MAX -- JOB이 아닌 전체
FROM EMP
ORDER BY JOB, ENAME;
+ AVG
ROWS 윈도우를 이용해 원하는 조건에 맞는 데이터에 대한 통계값을 구하는 함수
- 같은 매니저 내에서 앞의 사번과 뒤의 사번의 평균을 구하는 예시
SELECT MGR, ENAME, HIREDATE, SAL,
ROUND (AVG(SAL) OVER (PARTITION BY MGR ORDER BY HIREDATE ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING))
as MGR_AVG
FROM EMP;
+ COUNT
파티션별 ROWS 윈도우를 이용해 원하는 조건에 맞는 데이터에 대한 통계값을 구하는 함수
- 본인보다 급여가 100 적은 직원부터 200 많은 직원까지의 총 직원 수를 구하는 예시
SELECT ENAME, SAL, COUNT(*) OVER (ORDER BY SAL RANGE BETWEEN 100 PRECEDING AND 200 FOLLOWING)
AS MOV_COUNT
FROM EMP;
행 순서 관련 함수
SQL Server에서는 지원하지 않는 함수
| 함수 | 함수 설명 |
| FIRST_VALUE | 파티션 별 윈도우에서 가장 먼저 나온 값 ( ≒ MIN 함수) |
| LAST_VALUE | 파티션 별 윈도우에서 가장 나중에 나온 값 ( ≒ MAX 함수) |
| LAG | 파티션 별 윈도우에서 해당 행의 이전 몇 번째 행의 값을 가져옴 |
| LEAD | 파티션 별 윈도우에서 해당 행의 이후 몇 번째 행의 값을 가져옴 |
+ FIRST_VALUE (or LAST_VALUE) 함수 예시
SELECT DEPTNO, ENAME, SAL, FIRST_VALUE(ENAME) OVER (PARTITION BY DEPTNO ORDER BY SAL DESC, ENAME ASC)
AS RICH_EMP
FROM EMP;
+ LAG (or LEAD) 함수 예시
- 가져올 값이 없으면 NULL로 표시된다.
SELECT ENAME, SAL,
LAG(SAL, 1) OVER (ORDER BY SAL DESC) AS HIGHER_SAL,
LEAD(SAL, 1) OVER (ORDER BY SAL DESC) AS LOWER_SAL
FROM EMP
WHERE JOB = 'SALESMAN';
+ LAG (or LEAD) 함수의 확장
- LAG(SAL, 2, 0) : 2번째 앞의 행을 가져오되, 가져올 행이 없는 처음 두 행의 값은 0으로 채운다.
SELECT ENAME, SAL,
LAG(SAL, 2, 0) OVER (ORDER BY SAL DESC) AS HIGHER_SAL
FROM EMP;
비율 관련 함수
+ RATIO_TO_REPORT
파티션 내 전체 SUM(칼럼)값에 대한 행별 칼럼 값의 백분율을 소수점으로 구하는 함수
- 동일 JOB 내에서 본인의 급여가 차지하는 비율을 구하는 예시
SELECT JOB, ENAME, SAL, ROUND(RATIO_TO_REPORT(SAL) OVER (PARTITION BY JOB), 2)
AS R_R
FROM EMP
ORDER BY JOB;
+ PERCENT_RANK
파티션별 윈도우에서 처음 나오는 값을 0으로, 마지막 나오는 값을 1로 하여, 행의 순서별 백분율을 구하는 함수
- 결과 값은 0 <= 결과값 <= 1의 범위를 가진다.
- 동일 JOB 내에서 본인의 급여가 상위 몇 %에 있는지 출력하는 예시
SELECT DEPTNO, ENAME, SAL,
100*(PERCENT_RANK() OVER
(PARTITION BY DEPTNO ORDER BY SAL DESC)) || '%' AS P_R
FROM EMP;
+ CUME_DIST
파티션별 윈도우의 전체건수에서 현재 행보다 작거나 같은 건수에 대한 누적백분율을 구하는 함수
- 결과 값은 0 < 결과값 <= 1의 범위를 가진다. (PERCENT_RANK와의 차이점)
- 동일 JOB 내에서 본인의 급여가 누적 순서 몇 %에 있는지 출력하는 예시
SELECT DEPTNO, ENAME, SAL,
ROUND(100*(CUME_DIST() OVER
(PARTITION BY DEPTNO ORDER BY SAL DESC)), 2 || '%' AS CUME
FROM EMP;
+ NTILE
파티션별 전체 건수를 ARGUMENT 값으로 N등분한 결과를 구하는 함수
- 전체 사원을 급여 순으로 정렬하고, 급여 기준 4개의 그룹으로 분리하는 질의를 작성하는 예시
SELECT ENAME, SAL, NTILE(4) OVER (ORDER BY SAL DESC) AS 급여구간
FROM EMP;
[관련 글 보러가기]
- [자격증 / SQLD] SQL 기본(1)_TABLE과 명령어(DML, DDL, DCL, TCL)
- [자격증 / SQLD] SQL 기본(2)_WHERE 조건절(연산자)과 함수
- [자격증 / SQLD] SQL 기본(3)_GROUP BY, ORDER BY, 조인(JOIN)
- [자격증 / SQLD] SQL 활용(1)_표준 조인과 집합 연산자
- [자격증 / SQLD] SQL 활용(2)_계층형 질의, 서브쿼리
- [자격증 / SQLD] SQL 활용(4)_절차형 SQL
[참고자료]
https://dataonair.or.kr/db-tech-reference/d-guide/sql/?pageid=4&mod=list
SQL – DATA ON-AIR
dataonair.or.kr
https://youtu.be/smMCZAx1zw4?si=_lNI6cM6EChwA9q5
'Certificate > SQLD' 카테고리의 다른 글
| [자격증] SQLD 준비하기_합격 후기 (0) | 2023.12.08 |
|---|---|
| [자격증 / SQLD] SQL 활용(4)_절차형 SQL (0) | 2023.11.03 |
| [자격증 / SQLD] SQL 활용(2)_계층형 질의, 서브쿼리 (1) | 2023.10.30 |
| [자격증 / SQLD] SQL 활용(1)_표준 조인과 집합 연산자 (1) | 2023.10.29 |
| [자격증 / SQLD] SQL 기본(3)_GROUP BY, ORDER BY, 조인(JOIN) (0) | 2023.10.29 |